这个是一个严肃的问题。
目的是为了抓取一批图片,大约几个T的样子。
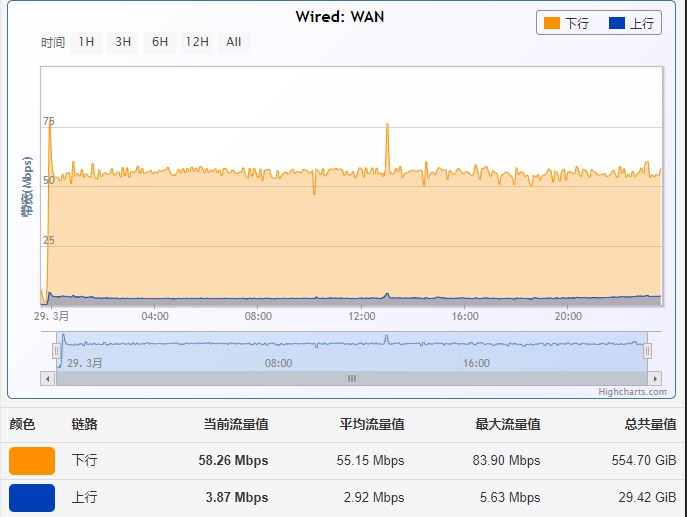
上次干这个活是在3月份,所以3月份打了一个草稿,今天补充下,附下今天的图,顺便把坑填了。
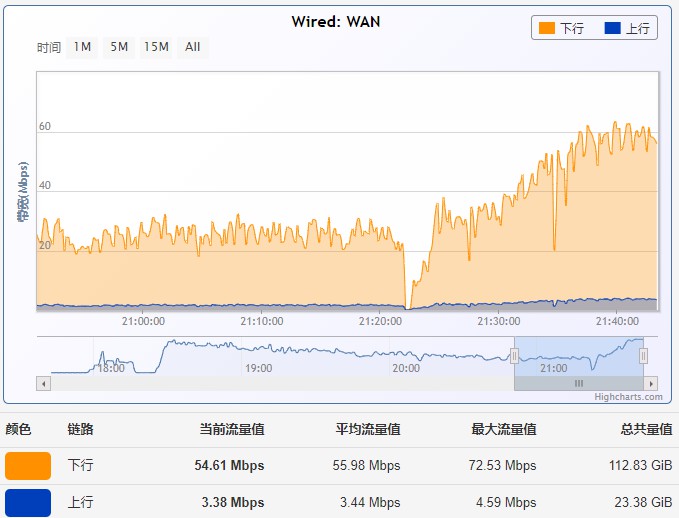
内存及负载使用状况:

针对的应用场景
- 对方不限速,无IP限制
- 对方有多个CDN
- 如图片爬取类的操作
采用的方案 (请忽略分布式爬虫下载)
- 单机家庭宽带
- 普通机械硬盘(无raid)
- 单机MySQL资源读取
- 机器内存16G
- 使用世界上最好的语言PHP
- 文件本机存储
优化的场景
- 多进程 250+
- 文件锁处理并发读取问题
- 直接读取26个IP,分散网络读取与减少DNS解析异常
- 单次读取100+记录,减少锁的等待问题
- 下载的文件先存内存
结论
要跑满100M,这种小文件难于登天,除非不差钱。
哦,图片哦
这个看的不是很明白